Why One AI Model Quietly Breaks Your Business Automations (2026)


Table of Contents
- Introduction
- Why does consolidating on one AI model concentrate failure risk for automations?
- What are AI hallucinations and why do they slip past normal monitoring?
- How does hybrid AI routing improve reliability and cut downtime?
- How can operators implement routing and failover without a machine learning team?
- What do invoice pipelines and customer chatbots teach us about single-model risk?
- Frequently Asked Questions (FAQs)
Introduction
When a team automates with artificial intelligence, the tidy version of the plan sounds obvious: pick a strong model, wire it into the workflow, and move on. One vendor, one API, one mental model for support and billing. For operators who are already underwater, that simplicity is not laziness. It is a rational response to complexity.
The problem is what happens after go-live. A single-model stack can feel clean on a diagram and still hide a structural flaw: every automation shares the same failure surface. When the model drifts after an update, when behavior shifts in a narrow domain you care about, or when outputs start looking right while being wrong, nothing fails loudly. Dashboards still show green. Latency looks fine. The vulnerability shows up as wrong numbers in a spreadsheet, a bad line on an invoice, or a confident answer about a policy that never existed.
This article makes a simple case that is uncomfortable for anyone who wanted AI to be a one-time procurement decision. Reliability in production is less about finding a perfect model and more about not betting the operation on any single one. Hybrid routing sends different tasks to different models based on fit, adds checks so bad outputs get caught, and keeps failover paths open when a provider hiccups or degrades. Teams experimenting with that architecture often report meaningful gains in reliability and less painful downtime than pure single-model setups. None of that requires you to become a machine learning researcher. It is mostly architecture, sampling, and honest ownership of what "done" means for each task.
Why does consolidating on one AI model concentrate failure risk for automations?
The appeal of one model is easy to name. Fewer integration paths, one security review surface, one relationship to manage when pricing or terms change. It is the same instinct that pushes teams toward one database or one cloud if they can get away with it. Consolidation is not automatically wrong. The issue is what you consolidate onto when the component is non-deterministic and can change without your roadmap.
Language models do not promise stable behavior the way a deterministic function does. Providers ship new versions, adjust safety layers, and retrain on new data. Sometimes the release notes read like pure wins. In real pipelines, a change that improves broad benchmarks can still break a narrow extraction rule your finance team relied on. If every critical flow points at the same endpoint, that breakage does not show up as one flaky job. It shows up as correlated failure: invoice parsing, support drafting, and internal summarization all skew together because they share one brain.
There is also a concentration-of-risk angle that has nothing to do with malice. When invoice processing, ticket triage, and compliance drafts all depend on the same underlying model, they inherit the same blind spots. A weakness in numerical grounding or long-context fidelity does not hit one workflow in isolation. It echoes across anything that trusted the same output style. You traded independent failure modes for operational simplicity, and simplicity stopped being free the moment the shared component lied convincingly.
Detection makes this worse, not better, in a cruel way. A timeout throws an error you can alert on. A hallucination often returns HTTP 200 with polished text. Your monitors confirm the service is alive. The business learns about the problem from a customer, an auditor, or someone doing spot checks days later. By then you are not debugging a single bad call. You are asking how much bad data already propagated.
What are AI hallucinations and why do they slip past normal monitoring?
A hallucination, in the practical sense operators care about, is confident text that reads like a correct answer but is not grounded in the facts you needed.
A hallucination, in the practical sense operators care about, is confident text that reads like a correct answer but is not grounded in the facts you needed. Large language models are built to continue plausible text, not to certify truth. That distinction matters when you route them straight into systems of record.
The models most teams deploy have gotten better at reasoning and fluency. In some settings that increases the risk profile for silent errors, because mistakes arrive with the same tone and structure as good answers. You do not get a flashing warning that says "I am guessing." You get a paragraph that looks audit-ready until someone who knows the domain reads it carefully.
That is why normal uptime monitoring is the wrong mental model. You are not only watching for outages. You are watching for semantic drift, invented citations, wrong line items, and policy language that was never approved. Those failures do not map cleanly to red graphs. They map to trust erosion, rework, and in customer-facing settings, liability when someone acts on bad guidance. Public disputes around chatbots inventing fare or policy details are a blunt reminder that "the model answered" is not the same as "the answer was allowed."
Regulatory and legal attention to AI outputs has been rising, which pushes hallucinations from a research talking point into a governance topic. Even if your industry is less exposed than aviation or medicine, the pattern is the same: once outputs touch money, customers, or compliance, "probably right" is not a release criterion.
How does hybrid AI routing improve reliability and cut downtime?
Hybrid routing is a deliberately boring name for a useful idea. Instead of one model for every task, you route work based on what each step needs. Extraction-heavy work goes toward models that behave well on structured documents. Reasoning-heavy steps might use a different profile. Customer language and intent classification might use another. The goal is not to collect models like trophies. It is to match task shape to model strength so a weakness in one area does not poison unrelated workflows.
Routing can stay simple at first. Rule-based switches are enough for many teams: if the payload looks like a PDF invoice, take path A; if it is a support ticket, take path B. You can grow into richer routing later, including confidence scores and automatic escalation, without blocking the first iteration on perfect sophistication.
Failover is the second half of the story. If a provider has an outage, rate limits you hard, or starts returning garbage for a class of inputs, another model can take the request. Redundancy is not only about vendor reliability. It is about giving yourself a lever when behavior changes and you need time to re-evaluate prompts, schemas, or evaluation sets without freezing the business.
The third layer is verification. Hybrid setups work best when outputs do not flow straight to production without checks when the stakes are high. That might mean schema validation, cross-checks against a trusted database, duplicate extraction with a smaller specialist model, or human review queues for borderline scores. The point is to turn silent failure into detected failure. Teams that combine routing, redundancy, and checks often report fewer catastrophic weeks than teams that run one model and hope.
Published anecdotes and early adopters sometimes cite substantial reliability improvements and roughly half the downtime versus single-model setups when they measure end-to-end automation health. Your numbers will depend on domain and discipline, but the mechanism is intuitive: you have reduced correlation between failures and added places where the system can say "stop, this needs another path."
Which business tasks should you route to different models first?
Start where mistakes cost the most or spread the fastest. Invoice and payment-adjacent flows are an obvious tier because wrong numbers compound. Anything that quotes policy to a customer belongs in another tier because reputational and legal risk sits close to the surface. Internal summarization for low-stakes prep reads can often tolerate more variance, which means it should not steal attention from higher-risk lanes when you are capacity constrained.
Within a single business process, split steps rather than treating the workflow as one blob. Normalization and field extraction are different jobs from narrative reasoning. Routing per step also makes evaluation easier: you can benchmark extraction with labeled samples without conflating scores with how well the model writes email prose.
If you are unsure where to begin, run a two-week sampling exercise. Take real inputs, run them through two or three candidate models, and score outputs against a human-approved rubric. You are not looking for a winner forever. You are looking for separation: places where model A is clearly stronger than model B for a defined task. That separation is what justifies routing rules you can defend to finance and IT.
How can operators implement routing and failover without a machine learning team?
You do not need a research lab. You need clear task categories, honest evaluation, and orchestration that can branch. The workflow looks like this: name the task types you actually run, pick evaluation sets per type, compare a short list of models or endpoints on real data, encode routing rules, then add failover and quality gates before outputs commit.
Task categorization is the step people skip because it feels bureaucratic. It is the whole game. "Automate customer success" is not a task type. "Classify inbound ticket intent," "draft first reply from approved templates," and "summarize a call transcript" are. Each has different correctness criteria and different tolerance for creativity.
Once categories exist, routing rules are mostly an engineering and policy exercise. Conditional logic in your integration layer may be enough at small scale. Many teams eventually move the graph into a workflow engine so retries, logging, and versioning live in one place. If you already orchestrate other systems, AI steps should sit in the same discipline, not as a special snowflake that bypasses change control.
Detection and failover belong in the same program of work as routing, not as phase three next year. A secondary model for critical paths is often cheaper than emergency cleanup after bad data lands in downstream systems. Human review for low-confidence scores is not a failure of automation. It is the admission that some decisions should stay supervised until your metrics prove you can relax the guardrails.
What do invoice pipelines and customer chatbots teach us about single-model risk?
Concrete stories stick because they sound like bad luck but trace back to structure. A finance automation that misreads line items after a model update is a textbook correlated failure: the service never went down, so nobody got paged, yet the books drifted. The fix is not only "more prompting." It is separation of extraction from downstream use, regression checks on labeled invoices, and a second path when scores wobble.
Customer-facing chatbots show how hallucinations become operational incidents. When a bot invents a policy or fare detail, the customer does not experience a model limitation. They experience your company. The remediation work spans legal, support leadership, and engineering. A hybrid approach does not eliminate mistakes, but it reduces the chance that one model's blind spot defines every customer touchpoint and every back-office job at the same time.
These cases share a lesson: fragile AI operations rarely fail because nobody cared. They fail because the architecture treated fluency as proof. Routing, redundancy, and verification are how you align the stack with how models actually behave.
Frequently asked questions
Quick answers on the topics covered in this article.
It is the practice of sending different automation steps to different models or endpoints based on what each step needs, instead of using one model for everything. It often includes backup paths when a provider fails or behaves badly.
Because every workflow shares the same failure modes and the same silent error patterns. An update or drift event can affect multiple departments at once, and hallucinations often look like healthy responses to monitoring tools.
It is model output that appears authoritative but is not faithful to your sources, policies, or data. It is especially dangerous when it passes formatting checks and lands in systems of record.
Not for a first version. You need clear task definitions, evaluation samples, routing rules, and orchestration discipline. ML specialists help at scale, but many teams start with rules and measured comparisons between existing APIs.
It reduces correlated failures by separating task types, adds failover when one endpoint degrades, and pairs well with automated checks so bad outputs trigger reroutes or human review instead of silent acceptance.
Start with money-adjacent flows, policy-quoting customer channels, and anything that feeds compliance evidence. Those have the highest cost when wrong.
Track task-level quality metrics, not only latency and error codes. Use golden datasets, spot audits, schema validation, and duplicate extraction for high-risk fields. Treat semantic drift as a first-class incident category.
It can add cost because you may call more than one system or keep standby endpoints. The trade is usually favorable when you include rework, reputational risk, and downtime from bad automation.
The concept scales down. Even two task types with two endpoints and a simple switch is hybrid routing. The architecture matters more than the headcount.
Stop asking which model is best in the abstract. Ask which model is best for each task, how you will verify outputs, and what happens when confidence drops. Resilience is structural, not heroic.
Share this article
Related workflows
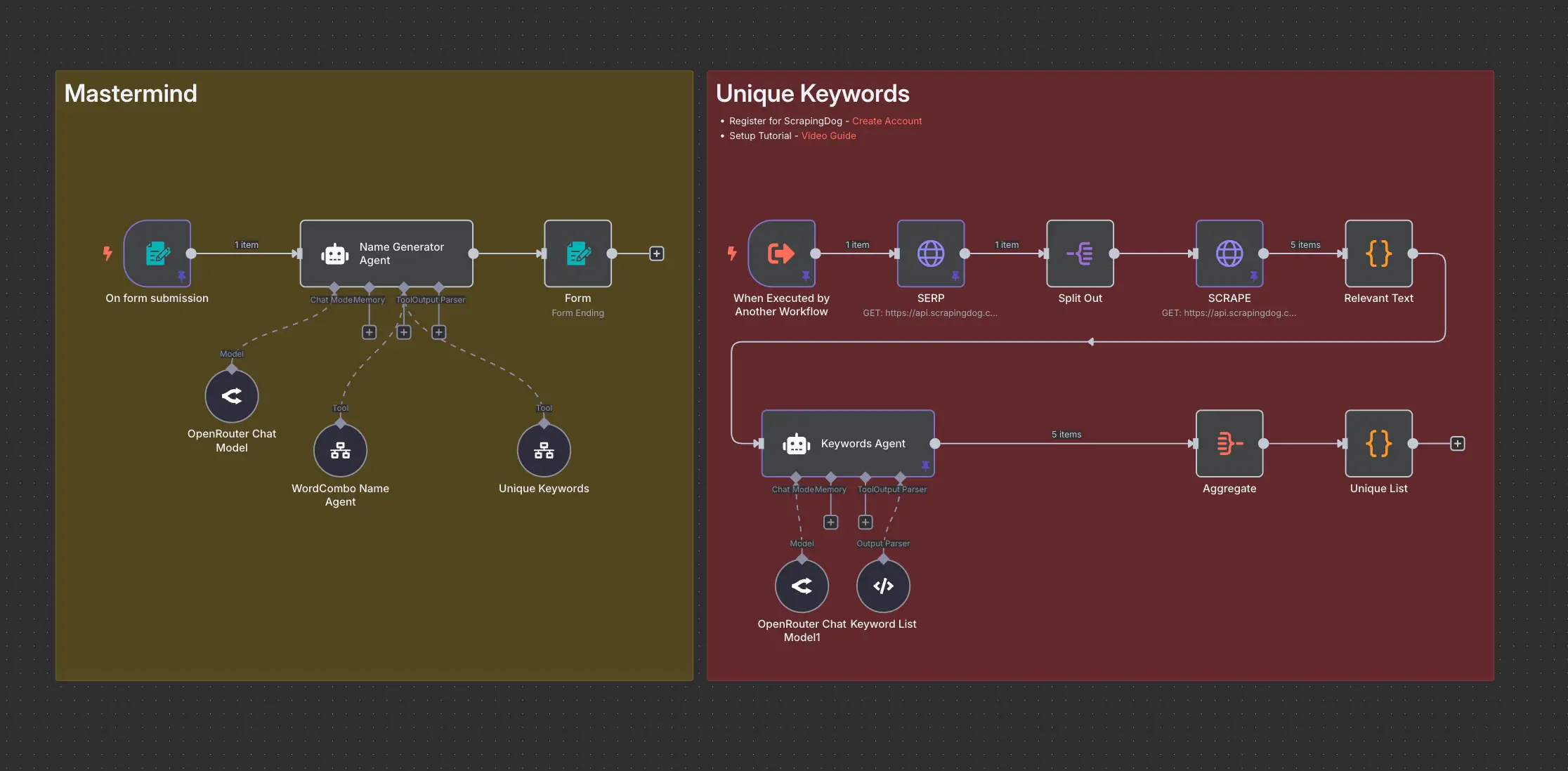
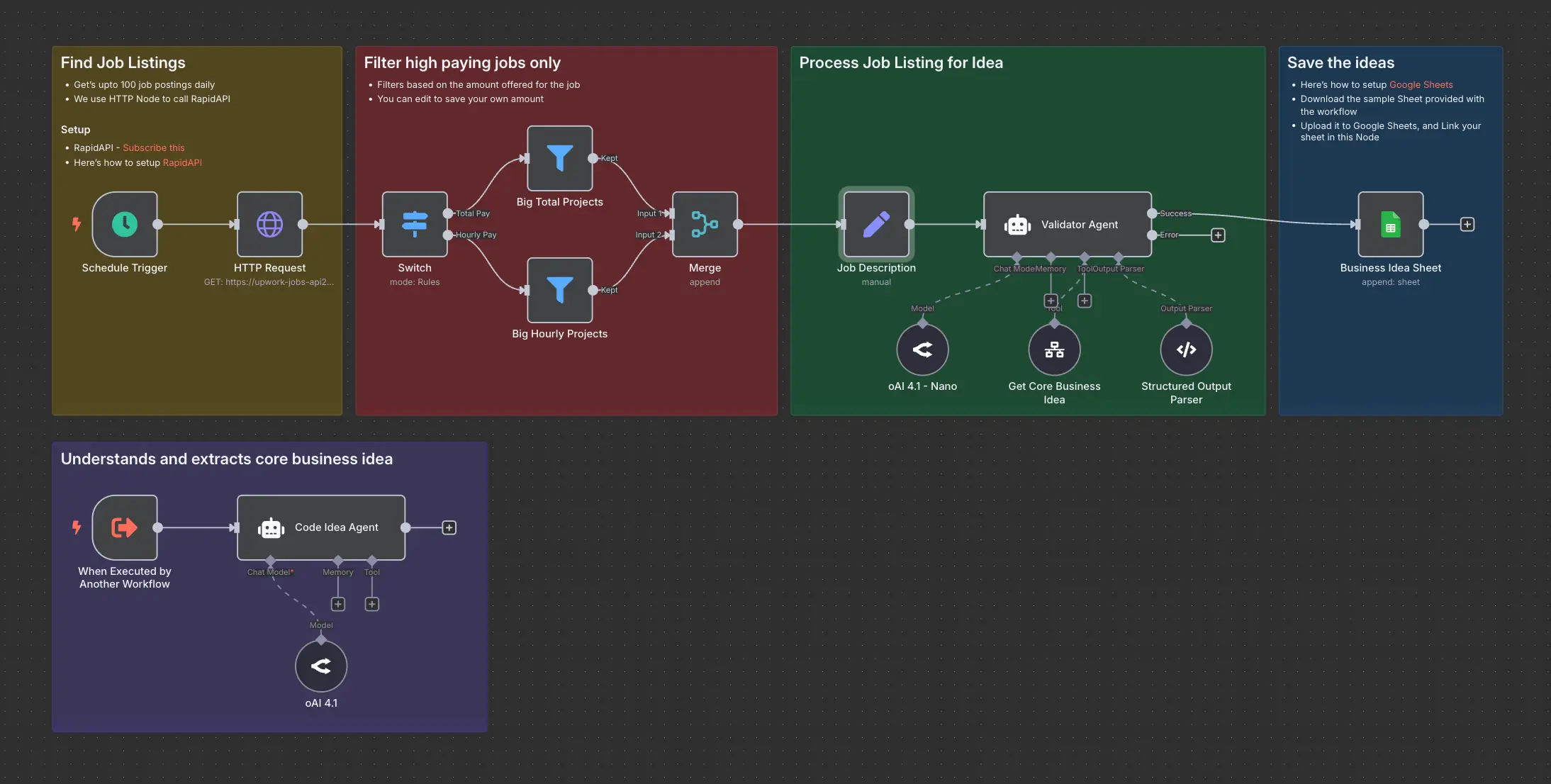
Domain Name Generator n8n workflow using ScrapingDog
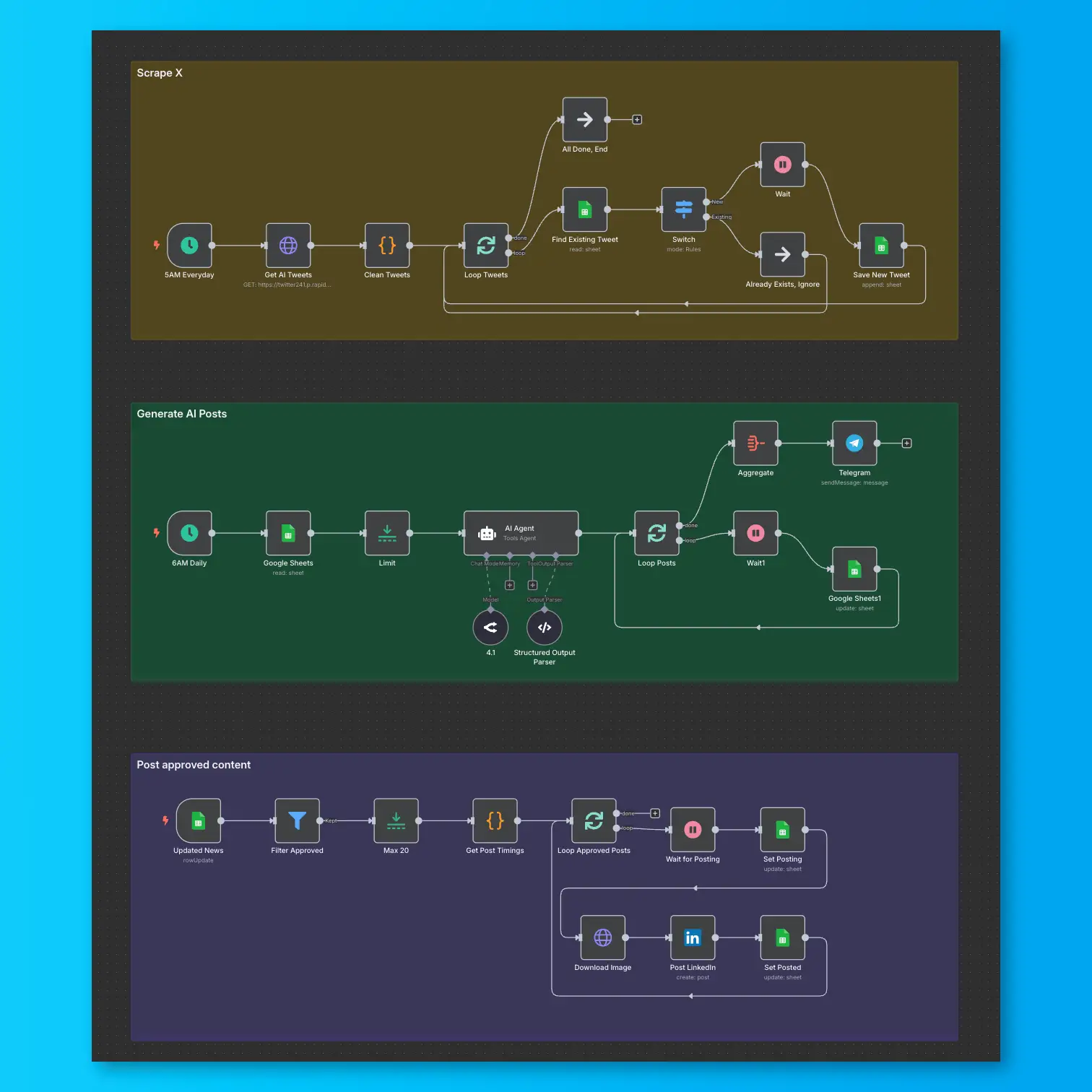
LinkedIn Automation From X Posts