Why Your AI Agents Stall on Big Tasks But Crush 10-Minute Jobs


Table of Contents
- Introduction
- Why do businesses see a gap between AI investment and real productivity gains?
- What makes a micro-task different from a macro-task for an AI agent?
- How do you break a messy workflow into agent-ready steps?
- Why stack specialized small agents instead of one big agent?
- What does lead enrichment teach us about automation that actually ships?
- How do ambiguity, judgment chains, and finish lines decide what to automate?
- How should teams measure ROI and govern agentic workflows in 2026?
- Frequently Asked Questions (FAQs)
Introduction
There is a story you hear after almost every AI pilot: leadership funds an agent, the demo looks magical, and six weeks later nobody trusts the output. The easy explanation is that the technology is not ready. That is usually the wrong conclusion.
Agents do not fail at automation in the abstract. They fail at vague, hour-long tasks where success is undefined, the chain of judgment calls is long, and nobody agreed on a finish line. Hand an agent a fuzzy goal like "manage our pipeline better" and it will either stall, hallucinate a plan, or produce something you cannot sign off on. Hand it a discrete job that takes a human five to ten minutes when the steps are obvious, and it tends to perform.
The speedup people talk about rarely comes from one giant brain doing everything. It comes from decomposing messy work into small, well-defined tasks and stacking agents (and humans) so each step has clear inputs, clear outputs, and a way to verify completion. This article walks through why that pattern matters, how to break workflows down without boiling the ocean, and what "good" looks like in lead enrichment and similar CRM-adjacent automations.
If you take one idea from the rest of this piece, let it be this: blame the task shape before you blame the model. When the work is fuzzy, the failure mode looks like "the AI is not smart enough." When the work is scoped, the same stack often feels almost boring because it simply runs. That boredom is what good automation feels like on the inside.
Why do businesses see a gap between AI investment and real productivity gains?
Adoption of AI in business functions has moved fast, but many organizations still see modest productivity gains compared with the headlines. A common pattern in analyst and industry reporting is that investment runs ahead of workflow design: tools get bolted on, pilots run in isolation, and nothing connects cleanly to how work actually happens.
Part of the problem is the mandate. Teams often ask an agent to "improve lead qualification" or "automate customer success" without spelling out what qualified means, which tradeoffs matter, or how to handle edge cases. Those are not automation requests. They are strategy questions disguised as tickets. Even strong humans need interviews, examples, and iteration before they can execute consistently.
Another issue is fragmentation. An agent might draft an email, or summarize a call, then stop because the next step lives in another system with no contract for data or responsibility. The work is still manual around the edges, so end-to-end cycle time barely moves.
The organizations that pull ahead tend to treat agents as part of an orchestrated workflow, not as a chatty oracle. They define handoffs, error paths, and human review gates. They accept that integration and governance are the product, not an afterthought. Once you see the gap as a process design problem rather than a model problem, the path forward gets much clearer.
There is another subtle trap: mistaking assistance for autonomy. A model that drafts a decent email still did not automate your outbound program if someone must paste, personalize, log activity, and schedule follow-ups by hand. Each of those steps is a candidate for either explicit automation or an explicit decision that it stays human. Leaving them in limbo is how you get "we use AI everywhere" with no hours back on the calendar.
What makes a micro-task different from a macro-task for an AI agent?
A micro-task is short, bounded, and checkable. Examples: pull a job title and company from a profile, validate a phone format, fetch a funding round from a trusted source, or map a title to "likely decision-maker" using rules you already use in hiring. When the agent is done, everyone can agree it is done because the artifact is defined in advance.
A macro-task is open-ended. "Rethink our content strategy" or "own renewals for the quarter" depends on taste, politics, and context that shift week to week. There is no obvious endpoint and no single test for correctness. Models can assist with research and drafts here, but calling that "full automation" sets you up for disappointment.
Customer support is a useful contrast. Many support interactions are micro-tasks: look up an order, explain a policy, issue a refund to a documented standard. That is why well-scoped bots can resolve a large share of volume with measurable satisfaction scores. Strategic account planning is not the same shape of problem. The mistake is assigning both to an agent with the same expectations.
If you are unsure which bucket you are in, ask: could a careful junior follow a written checklist and finish in one sitting without calling you? If yes, you are probably in micro-task territory. If the answer is "it depends on seventeen things," you still have a decomposition problem to solve before you automate.
Time horizon matters too. A micro-task can still be expensive in compute or API calls, but it should be conceptually short. When you catch yourself saying "the agent will work on this all afternoon," you are usually describing a project, not a task. Projects need milestones, owners, and checkpoints. Tasks need definitions of done.
How do you break a messy workflow into agent-ready steps?
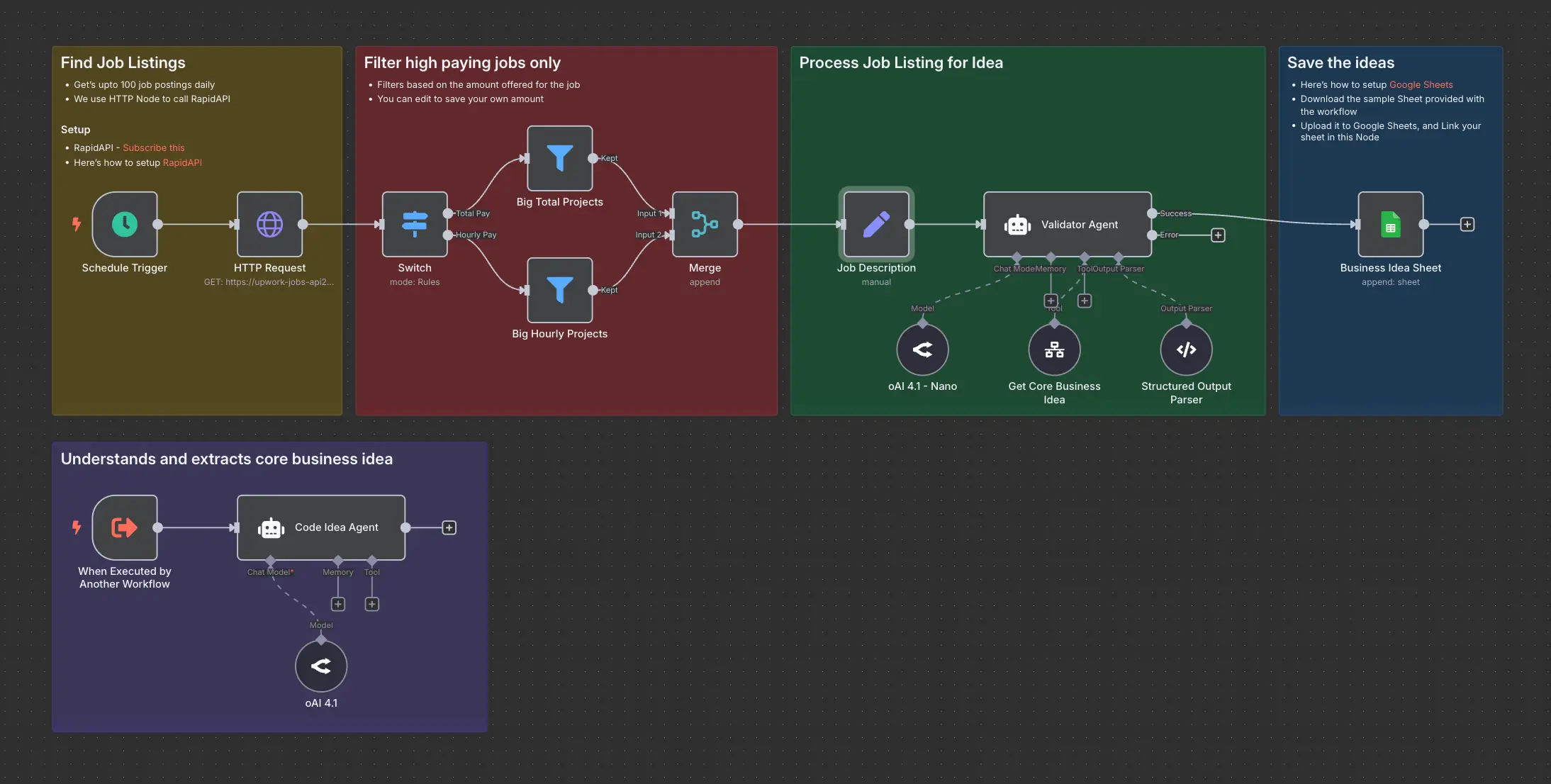
Workflow decomposition is the boring work that makes agents reliable. You start from a real process, not a slide deck version of it. For a qualification flow, you might end up with something like this: normalize company data from messy sources, score fit with explicit rules, route borderline cases to a human, find decision-maker contacts, verify and enrich them, then draft outreach from approved templates.
Each step should list inputs, transformations, outputs, and what to do when data is missing or contradictory. Step three might be "human reviews scores between 40 and 60." Step five might be "if verification fails twice, flag for manual research." The point is to drain ambiguity out of the agent's lane and push it to named owners.
This is where orchestration tools earn their keep. You are not looking for magic; you are looking for durable pipes between systems, retries, logging, and a place to version the workflow as rules change. If your organization already lives in that mindset, agents plug in as specialized workers instead of loose ends.
Documenting inputs, outputs, and exceptions
Teams that skip written specs almost always pay for it in silent failures. At minimum, capture: what file or API the agent reads, what schema it must write, how you measure accuracy on a sample set, and which exceptions escalate. That packet doubles as onboarding for the next engineer and as an audit trail when something goes wrong in production.
Why stack specialized small agents instead of one big agent?
A specialized agent does one job with narrow context. It is easier to test, easier to monitor, and easier to replace when the vendor or model changes. You can score "contact found and verified" without conflating it with "email tone quality."
A general-purpose agent that is supposed to research, score, write, and update the CRM in one run is fragile. One weak step poisons the trace. Debugging becomes a mess because responsibilities blur.
Stacking also matches how you iterate. If enrichment quality drops, you fix enrichment prompts, data sources, or parsers without touching outreach logic. Product teams have known this pattern for years; it is the same idea applied to LLM steps.
The handoff between agents needs the same discipline as handoffs between people: explicit payloads, idempotent writes where possible, and monitoring on latency and error rates per stage.
What does lead enrichment teach us about automation that actually ships?
Lead enrichment is the clean teaching example. A useful pipeline might: identify the company, align it to your CRM account, pick likely contacts, verify email and role, append firmographic fields, and format a record your reps recognize. Each piece is boring, repeatable, and measurable.
You can run much of that without a human in the loop when the rules are clear. Where fit is ambiguous or the data is adversarial, you stop and ask a person. That division of labor is not a compromise; it is the design.
Businesses that report durable ROI from agents often stopped chasing the biggest possible story. They got good at carving out sequences like this, then chained three or four wins in a row. The compound effect is where the "5x" feeling comes from, not from a single monolithic agent owning "sales."
How do ambiguity, judgment chains, and finish lines decide what to automate?
Ambiguity means the same instruction can mean different things to different stakeholders. Until you disambiguate, automation is guesswork. "Improve the pipeline" could mean velocity, margin, or volume. "Extract ARR from the last earnings statement" is narrower and machine-friendly.
A judgment chain is a sequence of calls that really need context, politics, or risk awareness. Hiring and enterprise deal qualification are full of them. AI can surface facts and options; it should not silently own the final call without guardrails.
A finish line is an objective end state: all rows processed, all tickets in a terminal status, all required fields populated. Agents need finish lines. Open-ended "keep optimizing" work belongs on a human roadmap with periodic reviews, not on an unattended loop.
Designing well means mapping these three concepts honestly. Automate where finish lines are clear, disambiguate before you scale, and insert humans into judgment chains on purpose, not by accident when something catches fire.
How should teams measure ROI and govern agentic workflows in 2026?
Speed of disciplined deployment is starting to matter as much as raw model capability. Teams that ship small scoped automations, measure them, and refine beat teams that perfect slides while pilots stall. A practical pattern is: pick one workflow with painful manual hours, decompose it, automate the obvious slices, instrument each slice, and only then broaden scope.
Pilot culture is shifting. Many organizations are comfortable spinning up experiments quickly, but still struggle to promote anything to "always on" infrastructure. The bridge is usually boring: monitoring, rollback, access control, and a named person who will fix the workflow when LinkedIn changes a field or your CRM validation rules update. If you cannot name that owner, you are not ready to call the workflow production-ready.
Governance is not bureaucracy when agents touch customer data and revenue systems. You need owners for the end-to-end flow, rules for escalation, and clarity when two agents disagree or duplicate work. Integration depth still separates teams that plateau from teams that scale: clean APIs, shared logging, and contracts between steps beat a pile of disconnected experiments.
If an agent cannot be tied to a KPI (time saved, error rate, conversion lift, tickets deflected), it will struggle to survive the next budget review. The good news is that forcing KPIs early usually forces clearer task definitions, which makes the automation more likely to work in the first place.
Frequently asked questions
Quick answers on the topics covered in this article.
Demos often use narrow, clean inputs and skip edge cases. Production has messy data, changing rules, and missing integrations. Close the gap by decomposing workflows, writing explicit success criteria, and testing on real samples before you scale.
A micro-task has clear inputs, a short execution path, and an objective completion check. A macro-task is open-ended, depends on judgment, and lacks a single finish line. Agents are reliable on the first and risky on the second unless you break it down.
A useful rule of thumb is the length of work a careful human could complete with a checklist in about five to ten minutes. If the task sprawls across hours or days of interpretation, you probably need more decomposition or a human owner.
Prefer several specialized agents with clear handoffs. Narrow scope improves reliability, monitoring, and iteration. One large agent doing everything mixes failure modes and makes debugging harder.
It means splitting a business process into smaller steps, each with defined inputs, outputs, and exception handling, so automation and humans each own what they do best.
Each sub-step (identify company, find contacts, verify, format for CRM) is repeatable and measurable. You can automate the mechanical parts and reserve human review for ambiguous or high-stakes cases.
A judgment chain is a series of decisions that need context, risk awareness, or stakeholder alignment. Agents can support these with data, but the final calls often still belong to people unless rules are explicit and audited.
It is an objective endpoint, such as "all rows enriched" or "ticket closed with reason code," so the system and operators agree when work is complete.
Start with one workflow, estimate hours saved or error reduction on a weekly sample, and track before-and-after metrics. If you cannot measure it, tighten the task scope until you can.
Name owners, define escalation paths, log decisions and errors, and document how data moves between systems. That stack keeps automation auditable when models and vendors change.
Share this article
Related workflows
Domain Name Generator n8n workflow using ScrapingDog
LinkedIn Automation From X Posts