Gemini 2.5 Pro: Breaking AI Benchmarks


Table of Contents
- Introduction
- Key Features of Gemini 2.5 Pro
- How Gemini 2.5 Pro is Crushing the Benchmarks
- Context Window Expansion: 1 Million to 2 Million Tokens
- Comparison with Other AI Models
- Conclusion
Gemini 2.5 Pro: Breaking All AI Benchmarks and Redefining Intelligence
Introduction
Artificial Intelligence is evolving rapidly, and Google’s latest release, Gemini 2.5 Pro, is at the forefront of this transformation. Dubbed Google’s most intelligent AI to date, it has been extensively tested across various benchmarks, often outperforming competitors like o3-mini, Grok 3 Beta, and Claude 3.7 Sonnet.
With benchmark scores exceeding expectations in reasoning, coding, and general knowledge tests, Gemini 2.5 Pro is proving itself as a leader in AI technology. But what sets it apart? And how does it compare to competitors? Let's dive deep into its capabilities, benchmarks, and what its impressive performance means for the AI landscape.
Key Features of Gemini 2.5 Pro
Gemini 2.5 Pro offers several cutting-edge advancements that contribute to its superior performance:
- Multimodal Capabilities: Supports text, images, audio, and video processing.
- 1 Million Token Context Window (Set to expand to 2 million): Allows it to efficiently process large documents, books, and extensive datasets.
- Advanced Reasoning: "Thinking models" that improve critical and logical analysis before responding.
- Superior Benchmark Performance: Outperforms competition in reasoning, complex coding tasks, and mathematical problem-solving.
These features make it a transformative tool for industries ranging from research and software development to education and general AI applications.
How Gemini 2.5 Pro is Crushing the Benchmarks
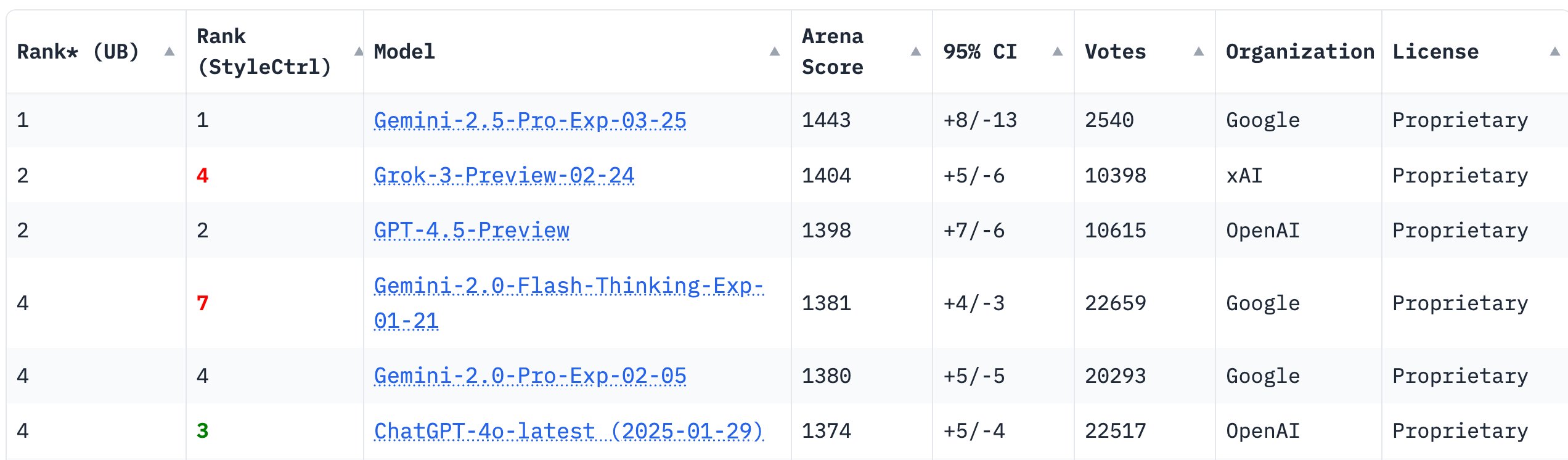
Benchmarks are the litmus tests for AI models, measuring their reasoning, coding efficiency, and general knowledge performance. Gemini 2.5 Pro has demonstrated groundbreaking achievements across multiple benchmarks.
1. LMArena Leaderboard: The Most Preferred AI
Metric: Evaluates human preference for AI-generated responses in interactive settings.
✅ Gemini 2.5 Pro scored the highest, indicating that users prefer its responses over competitors like Grok 3 Beta, Claude 3.7 Sonnet, and o3-mini.
| Model | Ranking on LMArena |
|---|---|
| Gemini 2.5 Pro | 🔥 Top Rank |
| Grok 3 Beta | Lower Rank |
| o3-mini | Below Gemini |
| Claude 3.7 Sonnet | Lower Rank |
💡 Takeaway: Gemini 2.5 Pro’s responses are judged more coherent, relevant, and preferred by users than competitors.
2. GPQA Benchmark: Graduate-Level Scientific Reasoning
Metric: Tests AI’s ability to handle graduate-level, Google-proof science questions.
✅ Gemini 2.5 Pro achieved an outstanding 84.0% score in GPQA Diamond, leading the field.
| Model | GPQA Diamond Score |
|---|---|
| Gemini 2.5 Pro | 🔥 84.0% |
| o3-mini | 79.5% |
| Grok 3 Beta | 80.2% |
| Claude 3.7 Sonnet | Lower Score |
💡 Takeaway: The model's reasoning skills make it a top-tier tool for complex scientific research and problem-solving.
3. AIME 2025: Outperforming in Mathematical Challenges
Metric: Performance in high-school level competitive math (AIME 2025).
✅ Gemini 2.5 Pro scored an astonishing 86.7%, narrowly surpassing o3-mini at 86.5%.
| Model | AIME 2025 Score (%) |
|---|---|
| Gemini 2.5 Pro | 🔥 86.7% |
| o3-mini | 86.5% |
| Grok 3 Beta | 84.2% |
| Claude 3.7 Sonnet | Lower Score |
💡 Implication: Gemini 2.5 Pro excels at mathematical reasoning, key for educational AI applications.
4. Humanity’s Last Exam: Broad Knowledge Test
Metric: Measures AI’s broad knowledge, reasoning, and problem-solving across science, math, and humanities.
✅ Gemini 2.5 Pro leads with 18.8%—significantly higher than Claude 3.7 Sonnet’s 8.9%.
| Model | Humanity's Last Exam Score (%) |
|---|---|
| Gemini 2.5 Pro | 🔥 18.8% |
| o3-mini | 14.0% |
| Claude 3.7 Sonnet | 8.9% |
| Grok 3 Beta | 12.0% |
💡 Insight: This test affirms Gemini’s deep understanding of both technical and general human knowledge inquiries.
5. Coding Benchmarks: Competing in Software Engineering
Gemini 2.5 Pro has been evaluated in real-world coding environments.
✅ Scores 63.8% on SWE-Bench Verified, showcasing strong agentic coding performance.
| Benchmark | Gemini 2.5 Pro Score | Top Competitor |
|---|---|---|
| SWE-Bench Verified | 63.8% | Claude 3.7 Sonnet |
| LiveCodeBench v5 | 70.4% | o3-mini (74.1%) |
| Aider Polyglot | 74.0% | Unspecified |
💡 Conclusion: While Gemini 2.5 Pro is highly effective in coding tasks, some competitors marginally outperform it in custom setups.
Context Window Expansion: 1 Million to 2 Million Tokens
A standout feature of Gemini 2.5 Pro is its 1 million token context window, with plans to expand it to 2 million. This will make it capable of processing entire books, legal documents, and extensive coding projects in a single pass.
Impact of Large Context Windows
- 📖 Better long-form understanding for in-depth text analysis.
- 🧠 Superior reasoning when dealing with complex problems.
- 💻 Enhanced coding abilities for larger projects.
This massive context expansion will set new standards, making AI truly contextual like never before.
Comparison with Other AI Models
Let’s see how Gemini 2.5 Pro stacks up against competition across key areas.
| Feature | Gemini 2.5 Pro | o3-mini | Claude 3.7 Sonnet | Grok 3 Beta |
|---|---|---|---|---|
| User Preference (LMArena) | ✅ Top | ❌ Lower | ❌ Lower | ❌ Lower |
| Scientific Reasoning (GPQA) | ✅ 84.0% | ❌ 79.5% | ❌ Lower | ❌ 80.2% |
| Math Performance (AIME 2025) | ✅ 86.7% | ❌ 86.5% | ❌ Lower | ❌ Lower |
| General Knowledge (Humanity’s Last Exam) | ✅ 18.8% | ❌ 14.0% | ❌ 8.9% | ❌ 12.0% |
| Coding (SWE-Bench) | ✅ 63.8% | ❌ Lower | ❌ Higher | ❌ Lower |
Conclusion
✅ Gemini 2.5 Pro dominates in reasoning-based benchmarks
✅ Excels in multimodal tasks, far beyond traditional AI responses
✅ Its 1 million token window is pushing AI capabilities to new limits
✅ Potential for growth with 2 million token expansion
Google’s Gemini 2.5 Pro is rewriting the AI landscape, leading in almost all key performance metrics. With future updates, it may cement its place as the most advanced AI system ever created.
Share this article
Related workflows
LinkedIn Automation From X Posts